Updated (see below)
People here in the northeast US consider this to have been an unusually warm winter. Was it?
The University of Dayton and the US Environmental Protection Agency maintain an archive of daily average temperatures that's reasonably current. In the case of Albany, NY (the most similar of their records to our homes in the Massachusetts' Pioneer Valley), the data set as of this writing includes daily records from 1995 through March 12, 2012.
In this entry, we show how to use R to plot these temperatures on a circular axis, that is, where January first follows December 31st. We'll color the current winter differently to see how it compares. We're not aware of a tool to enable this in SAS. It would most likely require a bit of algebra and manual plotting to make it work.
R
The work of plotting is done by the radian.plot() function in the plotrix package. But there are a number of data management tasks to be employed first. Most notably, we need to calculate the relative portion of the year that's elapsed through each day. This is trickier than it might be, because of leap years. We'll read the data directly via URL, which we demonstrate in Example 8.31. That way, when the unseasonably warm weather of last week is posted, we can update the plot with trivial ease.
library(plotrix)
temp1 = read.table("http://academic.udayton.edu/kissock/http/
Weather/gsod95-current/NYALBANY.txt")
leap = c(0,1,0,0,0,1,0,0,0,1,0,0,0,1,0,0,0,1)
days = rep(365, 18) + leap
monthdays = c(31,28,31,30,31,30,31,31,30,31,30,31)
temp1$V3 = temp1$V3 - 1994
The leap, days, and monthdays vectors identify leap years, count the corrrect number of days in each year, and have the number of days in the month in non-leap years, respectively. We need each of these to get the elapsed time in the year for each day. The columns in the data set are the month, day, year, and average temperature (in Fahrenheit). The years are renumbered, since we'll use them as indexes later.
The yearpart() function, below, counts the proportion of days elapsed.
yearpart = function(daytvec,yeardays,mdays=monthdays){
part = (sum(mdays[1:(daytvec[1]-1)],
(daytvec[1] > 2) * (yeardays[daytvec[3]]==366))
+ daytvec[2] - ((daytvec[1] == 1)*31)) / yeardays[daytvec[3]]
return(part)
}
The daytvec argument to the function will be a row from the data set. The function works by first summing the days in the months that have passed (,sum(mdays[1:(daytvec[1]-1)]) adding one if it's February and a leap year ((daytvec[1] > 2) * (yeardays[daytvec[3]]==366))). Then the days passed so far in the current month are added. Finally, we subtract the length of January, if it's January. This is needed, because sum(1:0) = 1, the result of which is that that January is counted as a month that has "passed" when the sum() function quoted above is calculated for January days. Finally, we just divide by the number of days in the current year.
The rest is fairy simple. We calculate the radians as the portion of the year passed * 2 * pi, using the apply() function to repeat across the rows of the data set. Then we make matrices with time before and time since this winter started, admittedly with some ugly logical expressions (section 1.14.11), and use the radian.plot() function to make the plots. The options to the function are fairly self-explanatory.
temp2 = as.matrix(temp1)
radians = 2* pi * apply(temp2,1,yearpart,days,monthdays)
t3old = matrix(c(temp1$V4[temp1$V4 != -99 & ((temp1$V3 < 18) | (temp1$V2 < 12))],
radians[temp1$V4 != -99 & ((temp1$V3 < 18) | (temp1$V2 < 2))]),ncol=2)
t3now= matrix(c(temp1$V4[temp1$V4 != -99 &
((temp1$V3 == 18) | (temp1$V3 == 17 & temp1$V1 == 12))],
radians[temp1$V4 != -99 & ((temp1$V3 == 18) |
(temp1$V3 == 17 & temp1$V1 == 12))]),ncol=2)
# from plottrix library
radial.plot(t3old[,1],t3old[,2],rp.type="s", point.col = 2, point.symbols=46,
clockwise=TRUE, start = pi/2, label.pos = (1:12)/6 * (pi),
labels=c("February 1","March 1","April 1","May 1","June 1",
"July 1","August 1","September 1","October 1","November 1",
"December 1","January 1"), radial.lim=c(-20,10,40,70,100))
radial.plot(t3now[,1],t3now[,2],rp.type="s", point.col = 1, point.symbols='*',
clockwise=TRUE, start = pi/2, add=TRUE, radial.lim=c(-20,10,40,70,100))
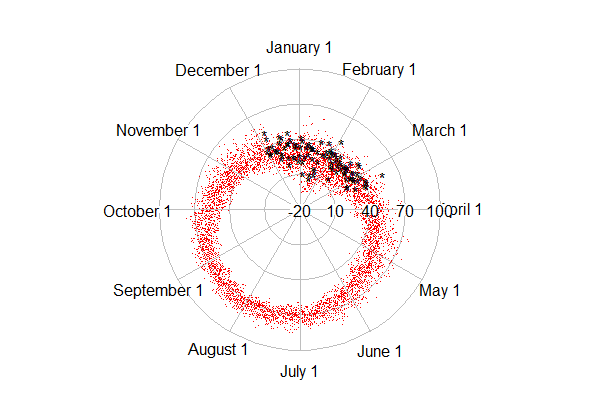
The result is shown at the top. The dots (point.symbol is like pch so 20 is a point (section 5.2.2) show the older data, while the asterisks are the current winter. An alternate plot can be created with the rp.type="p" option, which makes a line plot. The result is shown below, but the lines connecting the dots get most of the ink and are not what we care about today.

Either plot demonstrates clearly that a typical average temperature in Albany is about 60 to 80 in August and about 10 to 35 in January, the coldest monthttp://www.blogger.com/img/blank.gifh.
Update
The top figure shows that it has in fact been quite a warm winter-- most of the black asterisks are near the outside of the range of red dots. Updating with more recent weeks will likely increase this impression. In the first edition of this post, the radial.lim option was omitted, which resulted in different axes in the original and "add" calls to radial.plot. This made the winter look much cooler. Many thanks to Robert Allison for noticing the problem in the main plot. Robert has made many hundreds of beautiful graphics in SAS, which can be found here. He also has a book. Robert also created a version of the plot above in SAS, which you can find here, with code here. Both SAS and R (not to mention a host of other environments) are sufficiently general and flexible that you can do whatever you want to do-- but varying amounts of expertise might be required.
An unrelated note about aggregators
We love aggregators! Aggregators collect blogs that have similar coverage for the convenience of readers, and for blog authors they offer a way to reach new audiences. SAS and R is aggregated by R-bloggers and PROC-X with our permission, and by at least 2 other aggregating services which have never contacted us. If you read this on an aggregator that does not credit the blogs it incorporates, please come visit us at SAS and R. We answer comments there and offer direct subscriptions if you like our content. In addition, no one is allowed to profit by this work under our license; if you see advertisements on this page, the aggregator is violating the terms by which we publish our work.





{kind=link}